Dynamic Programming¶
1. Dice Combinations¶
\(F[i] = \sum_{j = 1}^{min(i, 6)}{F[i - j]}\)
const int MOD = 1'000'000'000 + 7;
void solve() {
int n;
cin >> n;
vector<int> f(n + 1);
f[0] = 1;
for(int i = 1; i <= n; ++i) {
for(int j = 1; j <= min(i, 6); ++j) {
f[i] = (f[i] + f[i - j]) % MOD;
}
}
cout<<f[n]<<endl;
}
空間壓縮,F[i] 只跟前六個有關。
const int MOD = 1'000'000'000 + 7;
const int sides = 6;
void solve() {
int n, nxt;
cin >> n;
vector<int> f(sides);
f[0] = 1;
for(int i = 1; i <= n; ++i) {
nxt = 0;
for(int j = 1; j <= min(i, 6); ++j) {
nxt = (nxt + f[((i - j) % sides + sides) % sides]) % MOD;
}
f[i % sides] = nxt;
}
cout<<f[n % sides]<<endl;
}
2. Minimizing Coins¶
\(F[i] = min(F[i], F[i - c_j] + 1)\)
這題要注意的地方,內外層的 for-loop 可以交換計算不影響答案,但若是內層 for-loop 為 \(c_j\) 的 [1, n] 會比內層 for-loop 是 [1, x] 時還慢 => cache locality。
void solve() {
int n, x;
cin >> n >> x;
vector<int> c(n), f(x + 1, inf);
readv(n, c[i]);
f[0] = 0;
for(int j = 0; j < n; ++j) {
for(int i = 1; i <= x; ++i) {
if(i - c[j] >= 0)
chmin(f[i], f[i - c[j]] + 1);
}
}
if(f[x] >= inf)
cout<<-1<<endl;
else
cout<<f[x]<<endl;
}
3. Coin Combinations I¶
\(F[i] = \sum_{j = 1}^{n}{F[i - c_j]}\)
這題要注意的是模數的計算會非常花費時間,因此先用 long long 的 tmp 加法,最後再做模數計算可以增加整體的效能。
const int MOD = 1'000'000'000 + 7;
void solve() {
int n, x;
cin >> n >> x;
vector<int> c(n), f(x + 1);
readv(n, c[i]);
f[0] = 1;
ll tmp = 0;
for(int i = 1; i <= x; ++i) {
tmp = 0;
for(int j = 0; j < n; ++j) {
if(i - c[j] >= 0)
tmp += f[i - c[j]];
}
f[i] = (tmp % MOD);
}
cout<<f[x]<<endl;
}
4. Coin Combinations II¶
這題是求組合數,因此像是 2 + 3, 3 + 2 這種重複組合要去重,透過將遍歷硬幣的 for-loop 放在外層,可以避免重複。
要注意的地方是內層 for-loop 的範圍會是 \([c_j, x]\)
const int MOD = 1'000'000'000 + 7;
void solve() {
int n, x;
cin >> n >> x;
vector<int> c(n), f(x + 1);
readv(n, c[i]);
f[0] = 1;
for(int j = 0; j < n; ++j) {
for(int i = c[j]; i <= x; ++i) {
f[i] += f[i - c[j]];
if(f[i] >= MOD) f[i] -= MOD;
}
}
cout<<f[x]<<endl;
}
5. Removing Digits¶
\(F[x] = min(F[x - d_i]) + 1\),\(d_i\) 是 x 的 digit。
void solve() {
int n;
cin >> n;
vector<int> f(10, inf);
f[0] = 0;
for(int i = 1; i <= n; ++i) {
int x = i;
int nxt = inf;
while(x) {
int d = x % 10;
if(d) chmin(nxt, f[((i - d) % 10 + 10) % 10] + 1);
x /= 10;
}
f[i % 10] = nxt;
}
cout<<f[n % 10]<<endl;
}
6. Grid Paths I¶
const int MOD = 1'000'000'000 + 7;
vector<pii> dirs = {{0, 1}, {1, 0}};
void solve() {
int n;
cin >> n;
string row;
vector f(n + 1, 0);
f[1] = 1;
for(int i = 0; i < n; ++i) {
cin >> row;
for(int j = 0; j < n; ++j) {
if(row[j] == '*') {
f[j + 1] = 0;
} else {
f[j + 1] = (f[j + 1] + f[j]) % MOD;
}
}
}
cout<<f[n]<<endl;
}
7. Book Shop¶
限制個數背包,每個物品只能選一次,所以內層迴圈使用 \([x, prices_i]\)。注意最後輸出 F[X],陣列初始化是 0。
\(F[x] = max(F[x], F[x - prices_j] + pages_j)\)
void solve() {
int n, x;
cin >> n >> x;
vector<int> prices(n), pages(n);
readv(n, prices[i]);
readv(n, pages[i]);
vector<int> f(x + 1, 0);
f[0] = 0;
for(int i = 0; i < n; ++i) {
for(int j = x; j >= prices[i]; --j) {
chmax(f[j], f[j - prices[i]] + pages[i]);
}
}
cout<<f[x]<<endl;
}
8. Array Description¶
F[i][j] 定義為長度為 i 時以 j 為結尾的序列的個數。
因此轉移方程:
\(f[i][j] = \sum_{k = -1}^{1}{F[i - 1][j + k]}\)
-
當 j > 0 時只要計算 f[i][j]。
-
當 j == 0 計算 \(F[i][1:m]\)。
要注意的是若是序列為 ... 0, j_i, j_{i + 1}, 0 ...,且 abs(j_i - j_{i + 1}) > 1 表示無法構成合法序列,答案為 0。
const int MOD = 1'000'000'000 + 7;
void solve() {
int n, m, x;
cin >> n >> m;
vector<ll> f(m + 2, 0);
cin >> x;
if(x) {
f[x] = 1;
} else {
ranges::fill(f.begin() + 1, f.end() - 1, 1);
}
int pre = x;
for(int i = 1; i < n; ++i) {
cin >> x;
vector<ll> nxt(m + 2, 0);
if(x) {
if(pre > 0 && abs(x - pre) > 1) {
cout<<0<<endl;
return;
}
nxt[x] = (f[x - 1] + f[x] + f[x + 1]) % MOD;
} else {
for(int j = 1; j <= m; ++j) {
nxt[j] = (f[j - 1] + f[j] + f[j + 1]) % MOD;
}
}
f = move(nxt);
pre = x;
}
if(x) {
cout<<f[x]<<endl;
}
else {
ll sum = reduce(f.begin(), f.end(), 0LL) % MOD;
cout<<sum<<endl;
}
}
9. Counting Towers¶
觀察最後兩層的圖形會有下面這些 pattern:
/*
0: 1: 2: 3: 4: 5: 6: 7:
_ _ _ _ ___ _ _ _ _ _ _ ___ ___
|_|_| |_|_| |___| |_| | | |_| | | | |___| | |
|_|_| |___| |_|_| |_|_| |_|_| |_|_| |___| |___|
*/
所有的 tower 都是由這些 pattern 串接而成,例如
觀察每個 pattern 頂部的兩格能否跟上方 pattern 的底層兩格連接會有如下的轉移方程:
接著化簡:
消除重複項:
調整一下編號:
時間複雜度為 O(n),但是如果有多個 testcase,會重複計算很多次,因此可以一開始就把全部的結果算出來,最後再回答即可。
const int MOD = 1'000'000'000 + 7;
const int MX = 1'000'000;
ll F[MX + 1];
auto init = []() {
vector<ll> f(2, 1);
F[1] = 2;
F[2] = 8;
for(int i = 3; i <= MX; ++i) {
ll f0 = f[0];
f[0] = (f[0] * 4 + f[1]) % MOD;
f[1] = (f0 + f[1] * 2) % MOD;
F[i] = (f[0] * 5 + f[1] * 3) % MOD;
}
return 0;
}();
void solve() {
int n;
cin >> n;
cout<<F[n]<<endl;
}
由上方的轉移方程可以得到下面的矩陣形式:
因此可以使用矩陣快速冪計算,時間複雜度為 \(O(m^3\log{(n)}) \text{ , for } m = 2\)
const int MOD = 1'000'000'000 + 7;
using Matrix_t = vector<vector<long long>>;
Matrix_t mul(Matrix_t &a, Matrix_t &b) {
const int m = a.size(), n = b[0].size();
Matrix_t mat = Matrix_t(m, vector<long long>(n, 0));
for(int i = 0; i < m; ++i) {
for(int k = 0; k < a[i].size(); ++k) {
for(int j = 0; j < n; ++j) {
if(!a[i][k]) continue;
mat[i][j] = (mat[i][j] + a[i][k] * b[k][j]) % MOD;
}
}
}
return mat;
}
Matrix_t identity_mat(int n) {
Matrix_t mat(n, vector<long long>(n, 0));
for(int i = 0; i < n; ++i) {
mat[i][i] = 1;
}
return mat;
}
Matrix_t mat_qpow(Matrix_t &x, int n) {
Matrix_t ans = identity_mat(x.size());
while(n) {
if(n & 1) ans = mul(x, ans);
x = mul(x, x);
n >>= 1;
}
return ans;
}
void solve() {
int n;
cin >> n;
if(n == 1) {
cout<<2<<endl;
return;
}
Matrix_t M = {{4, 1}, {1, 2}};
Matrix_t f0 = {{1}, {1}};
M = mat_qpow(M, n - 1);
M = mul(M, f0);
cout<<(M[0][0] + M[1][0]) % MOD <<endl;
}
- Kitamasa
時間複雜度 \(O(k^2\log{(n)})\),這裡 k = 2。這個方法比矩陣快速冪更快。
把上面矩陣表達式寫成如下:
這題所求的是 \(F_n\),但是 kitamsa 要使用遞迴式的形式,ex: fibonacci \(F(n) = F(n - 1) + F(n - 2)\)。
由特徵多項式可得:
由 Cayley–Hamilton:
乘上 \(F_n = c^Tx_n\)。(\(c^Tx_n\) 是用一組權重 \(c = \begin{bmatrix} \alpha \\ \beta\end{bmatrix}\),對狀態向量 \(x_n = \begin{bmatrix} f_n \\ g_n\end{bmatrix}\) 做線性加權,得到真正關心的輸出 \(F_n = \begin{bmatrix} 1 & 1 \end{bmatrix} \begin{bmatrix} f_n \\ g_n\end{bmatrix}\))
由前面可知 \(x_{n+1} = Ax_n\),\(x_{n+2}=A^2x_n\)
const int MOD = 1'000'000'007;
//f(n) = coef[k - 1] * f[n - 1] + coef[k - 2] * f[n - 2] + ... + coef[0] * f[n - k]
//init val f(i) = a[i] (0 <= i < k)
//return f(n) % MOD
//O(k^2 log n)
int qpow(int x, long long n) {
int res = 1;
while(n) {
if(n & 1) res = (res * x) % MOD;
x = (x * x) % MOD;
n >>= 1;
}
return res;
}
int kitamasa(const vector<int>& coef,const vector<int>& a, long long n) {
if(n < a.size()) {
return a[n] % MOD;
}
int k = coef.size();
if(k == 0) return 0;
if(k == 1) return 1LL * a[0] * qpow(coef[0], n) % MOD;
auto compose = [&](const vector<int>& A, vector<int> B) -> vector<int> {
vector<int> C(k);
for (int v : A) {
for (int j = 0; j < k; j++) {
C[j] = (C[j] + 1LL * v * B[j]) % MOD;
}
int bk1 = B.back();
for (int i = k - 1; i > 0; i--) {
B[i] = (B[i - 1] + 1LL * bk1 * coef[i]) % MOD;
}
B[0] = 1LL * bk1 * coef[0] % MOD;
}
return C;
};
vector<int> res_c(k), c(k);
res_c[0] = c[1] = 1;
for (; n > 0; n /= 2) {
if (n % 2) {
res_c = compose(c, move(res_c));
}
c = compose(c, c);
}
long long ans = 0;
for (int i = 0; i < k; i++) {
ans = (ans + 1LL * res_c[i] * a[i]) % MOD;
}
return (ans + MOD) % MOD;
}
void solve() {
int n;
cin >> n;
vector<int> coef = {-7, 6};//f(n) = - 7f(n - 2) + 6f(n - 1);
vector<int> a = {2, 8};//F0 F1
cout<<kitamasa(coef, a, n - 1) <<endl;
}
10. Edit Distance¶
本質上是 LCS 但是沒有仔細想清楚,一開始想用最長的字串長度減去 LCS 的長度當作操作的次數,但是沒有考慮到像 s = 'NGPYCNPO', t = 'UQPXWVLGHC',這樣的例子 LCS 為 'PC' ,但是除了 P 之外的字符都可以直接增加或是替換得到答案,但若是使用前面的想法會需要額外操作。
這題的轉移方程如下,定義 \(f(i, j)\) 為當字串 s 長度為 i 且字串 t 長度為 j 時,需要的操作數使得 s 等於 t。
if \(s_i = t_j\)
else
初始值為:
void solve() {
string s, t;
cin >> s;
cin >> t;
const int n = s.length();
const int m = t.length();
vector f(2, vector<int>(m + 1, inf));
for(int j = 0; j < m; ++j) f[0][j + 1] = j + 1;
f[0][0] = 0;
for(int i = 0; i < n; ++i) {
f[(i + 1) % 2][0] = i + 1;
for(int j = 0; j < m; ++j) {
int &res = f[(i + 1) % 2][j + 1];
if(s[i] == t[j]) {
res = f[i % 2][j];
} else {
res = min({f[i % 2][j], f[i % 2][j + 1], f[(i + 1) % 2][j]}) + 1;
}
}
}
cout<<f[n % 2][m]<<endl;
}
11. Longest Common Subsequence¶
定義 \(f(i, j)\) 為當字串 s 長度為 i 且字串 t 長度為 j 時的 LCS。
if \(s_i = t_j\)
else
void solve() {
int n, m;
cin >> n >> m;
vector<int> a(n), b(m);
vector f(n + 1, vector<int>(m + 1, 0));
readv(n, a[i]);
readv(m, b[i]);
for(int i = 0; i < n; ++i) {
for(int j = 0; j < m; ++j) {
if(a[i] == b[j]) {
chmax(f[i + 1][j + 1], f[i][j] + 1);
} else {
f[i + 1][j + 1] = max(f[i + 1][j], f[i][j + 1]);
}
}
}
cout<<f[n][m]<<endl;
int i = n, j = m;
vector<int> ans;
while(i && j) {
if(f[i][j] == f[i - 1][j - 1] + 1 && a[i - 1] == b[j - 1]) {
ans.push_back(a[i - 1]);
i--;
j--;
} else {
if(f[i][j] == f[i - 1][j]) {
i--;
} else {
j--;
}
}
}
for(int i = ans.size() - 1; i >= 0; --i) {
cout<<ans[i]<<" ";
}
}
12. Rectangle Cutting¶
這題一開始直覺地想到 \(O(n^3)\) 的解法,但是因為超過 \(10^9\) 所以有點不敢寫,後來看到解答有利用對稱性將複雜度下降成 \(O(\frac{n^3}{2})\)
void solve() {
int n, m;
cin >> n >> m;
int mx = max(m, n);
vector f(n + 1, vector<int>(m + 1, inf));
for(int i = 1; i <= min(n, m); ++i) {
f[i][i] = 0;
}
for(int len = 1; len <= n; ++len) {
for(int width = 1; width <= m; ++width) {
int &res = f[len][width];
if(len == width) continue;
for(int i = 1; i <= len / 2; ++i) {
res = min(res, f[i][width] + f[len - i][width]);
}
for(int i = 1; i <= width / 2; ++i) {
res = min(res, f[len][i] + f[len][width - i]);
}
res++;
}
}
cout<<f[n][m]<<endl;
}
13. Minimal Grid Path¶
這題沒辦法使用簡單的貪心去選擇走訪方向是因為有可能會遇到相同的字母,此時無法貪心的選擇比較小的字母,沒辦法由當前位置確認字典序更小的方向。
觀察會發現從 (0, 0) 至反對角線位置的上構成的字串長度會一樣:
利用這個性質,可以看成一層一層的反對角線,字串第 k 位表示為第 k 層的反對角線上某一位置的字母。
所以思考方式會是類似 BFS 的方式,當前佇列為第 k 層反對角線上最小字母的位置,要往 k + 1 層反對角線位置的方向擴散,而要選的方向為字母最小的方向。
由這個方式佇列中的每個位置的字母都會是一樣的,代表的是由原點至當前佇列中位置的字串前綴都是相同且最小,
反對角線最多有 \(2n - 1\) 條,時間複雜度為 \(O(n^2)\)。
vector<pii> dirs = {{0, 1}, {1, 0}};
void solve() {
int n;
cin >> n;
vector<string> row(n);
readv(n, row[i]);
vector<pii> cur = {{0, 0}};
vector used(n, vector<int>(n, 0));
cout<<row[0][0];
for(int diag = 1; diag < 2 * n - 1; ++diag) {
vector<pii> nxt;
for(auto &[r, c]: cur) {
for(auto &[dr, dc]: dirs) {
int nr = r + dr, nc = c + dc;
if(nr >= n || nc >= n) continue;
if(used[nr][nc]) continue;
used[nr][nc] = 1;
auto update = [&](int y, int x) -> void {
if(!nxt.empty()) {
if(row[nxt.back().first][nxt.back().second] > row[y][x]) {
nxt.clear();
} else if(row[nxt.back().first][nxt.back().second] < row[y][x]) {
return;
}
}
nxt.emplace_back(y, x);
};
update(nr, nc);
}
}
cout<<row[nxt[0].first][nxt[0].second];
cur.clear();
char pre = 0;
for(auto &[r, c]: nxt) {
if(pre > 0 && row[r][c] != pre) {
break;
}
cur.emplace_back(r, c);
pre = row[r][c];
}
}
cout<<endl;
}
這題一開始的想會是由 DP 的方式出發,從原點開始,每次考慮上面和左邊的字串,會有如下的轉移方程,\(f(i, j)\) 為原點至 \((i, j)\) 可以構成的最小字典序字串:
但是這樣會有 \(O(n^3)\) 的複雜度,因為字串的比對所以多一個 n 的複雜度。
為了減少字串比對的複雜度,我們要透過壓縮的思想對反對角線上的前/後綴做排序,將排序後的大小關係作為接下來比較的依據。可以將複雜度降至 \(O(n^2 + n\log{n})\)
void solve() {
int n;
cin >> n;
vector<string> row(n);
readv(n, row[i]);
vector hash(n + 1, vector<int>(n + 1, n + 1));
for(int diag = 2 * n - 2; diag >= 0; --diag) {
vector<pii> v;
for(int r = 0; r < n; r++) {
int c = diag - r;
if(0 <= c && c < n) {
v.emplace_back(r, c);
}
}
int k = v.size();
vector<pii> order(k);
for(int i = 0; i < k; ++i) {
auto [r, c] = v[i];
int state = (n + 2) * (row[r][c] - 'a') + min(hash[r + 1][c], hash[r][c + 1]);
order[i] = {state, r};
}
ranges::sort(order);
int nxt = 0;
for(int i = 0; i < k; ++i) {
if(i == 0 || order[i].first != order[i - 1].first) {
nxt++;
}
int r = order[i].second;
int c = diag - r;
hash[r][c] = nxt;
}
}
int r = 0, c = 0;
cout<<row[r][c];
while(r < n - 1 || c < n - 1) {
if(hash[r + 1][c] < hash[r][c + 1]) {
r++;
} else c++;
cout<<row[r][c];
}
}
14. Money Sums¶
背包問題,用bitset優化 \(O(\frac{n \cdot s}{B})\),n 是陣列長度,s 是值域,B 為 32/64 bit。
bitset<1'000'00 + 1> f;
void solve() {
int n;
cin >> n;
vector<int> a(n);
int sum = 0;
for(int i = 0; i < n; ++i) {
cin >> a[i];
sum += a[i];
}
f[0] = 1;
for(auto &x: a) {
f |= (f << x);
}
cout<<(f.count() - 1)<<endl;
for(int x = 1; x <= sum; ++x) {
if(f[x]) cout<<x<<" ";
}
}
15. Removal Game¶
經典的博弈 DP,透過式子變形可以得到:
所以利用轉移方程 \(f(l, r) = max(-f(l + 1, r) + a[l], -f(l, r - 1) + a[r])\) 得到最大差值。
這裡要注意的是 \(a[i] \le 10^9\) 使得 sum 可能超過 int。
遞迴寫法:
void solve() {
int n;
cin >> n;
vector<int> a(n);
ll sum = 0;
for(int i = 0; i < n; ++i) {
cin >> a[i];
sum += a[i];
}
vector f(n, vector<ll>(n, -infll));
auto dfs = [&](auto &&dfs, int l, int r) -> ll {
if(l > r) return 0;
if(l == r) return a[l];
ll &res = f[l][r];
if(res != -infll) return res;
res = 0;
res = max(-dfs(dfs, l + 1, r) + a[l], -dfs(dfs, l, r - 1) + a[r]);
return res;
};
ll d = dfs(dfs, 0, n - 1);
cout<<(d + sum) / 2LL<<endl;
}
疊代寫法:
void solve() {
int n;
cin >> n;
vector<int> a(n);
ll sum = 0;
for(int i = 0; i < n; ++i) {
cin >> a[i];
sum += a[i];
}
vector f(n, vector<ll>(n, -infll));
f[n - 1][n - 1] = a[n - 1];
for(int l = n - 2; l >= 0; --l) {
f[l][l] = a[l];
for(int r = l + 1; r < n; ++r) {
f[l][r] = max(-f[l + 1][r] + a[l], -f[l][r - 1] + a[r]);
}
}
ll d = f[0][n - 1];
cout<<(d + sum) / 2LL<<endl;
}
16. Two Sets II¶
用狀態表示把 x 分到哪一個 set 中,要注意的是最後要除 2 去除重複統計,除 2 要再注意使用模反做乘法。
用遞迴寫法比較直覺:
const int MOD = 1'000'000'000 + 7;
ll qpow(ll x, int n) {
ll res = 1;
while(n) {
if(n & 1) res = (res * x) % MOD;
x = (x * x) % MOD;
n >>= 1;
}
return res;
}
void solve() {
int n;
cin >> n;
int offset = (1 + n) * n / 2;
if(offset & 1) {
cout<< 0 << endl;
return;
}
vector f(n + 1, vector<int>(offset * 2 + 1, -1));
auto dfs = [&](auto &&dfs, int i, int cur) -> int {
if(i == 0) {
return cur == 0;
}
int &res = f[i][cur + offset];
if(res != -1) return res;
res = (dfs(dfs, i - 1, cur + i) + dfs(dfs, i - 1, cur - i)) % MOD;
return res;
};
cout<<dfs(dfs, n, 0) * qpow(2, MOD - 2) % MOD<<endl;
}
因為分成兩個 set ,所以會是 sum / 2 的背包問題。
可以只統計 [1, n - 1] 將 n 固定在其中一個 set 避免重複統計,這樣就不需要最後除 2。
疊代:
const int MOD = 1'000'000'000 + 7;
void solve() {
int n;
cin >> n;
int offset = (1 + n) * n / 2;
if(offset & 1) {
cout<< 0 << endl;
return;
}
int tar = offset / 2;
vector<int> f(tar + 1, 0);
f[0] = 1;
for(int x = 1; x < n; ++x) {
for(int s = tar; s >= x; --s) {
f[s] = (f[s] + f[s - x]) % MOD;
}
}
cout<<f[tar]<<endl;
}
17. Mountain Range¶
直覺地想到從最高的山頂開始,假設站在最高的山頂往兩側看,可以飛到比現在位置矮一點的山頂,接著重複同樣動作。因此需要知道一個區間內的最高位置,可以使用線段樹快速得到一個區間內的最大值。
上面方法有一個問題是當有多個相同高度的山頂時,把相同高度的山頂看成分割點會把當前區間分割成多個子區間,那我們該選擇的是能夠有最長序列的子區間,選擇一個子區間後沒辦法跨越至另一個子區間,透過預處理分組儲存每個高度的下標,可以用二分得到當前區間內對應高度的位置,從而找到對應的子區間。
時間複雜度為 \(O(n\log{n})\)
// 模板来源 https://leetcode.cn/circle/discuss/mOr1u6/
// 线段树有两个下标,一个是线段树节点的下标,另一个是线段树维护的区间的下标
// 节点的下标:从 1 开始,如果你想改成从 0 开始,需要把左右儿子下标分别改成 node*2+1 和 node*2+2
// 区间的下标:从 0 开始
struct Node {
int x;
int idx;
};
template<typename T>
class SegmentTree {
// 注:也可以去掉 template<typename T>,改在这里定义 T
// using T = pair<int, int>;
int n;
vector<T> tree;
// 合并两个 val
T merge_val(T a, T b) const {
return max(a, b);
}
// 合并左右儿子的 val 到当前节点的 val
void maintain(int node) {
tree[node] = merge_val(tree[node * 2], tree[node * 2 + 1]);
}
// 用 a 初始化线段树
// 时间复杂度 O(n)
void build(const vector<T>& a, int node, int l, int r) {
if (l == r) { // 叶子
tree[node] = a[l]; // 初始化叶节点的值
return;
}
int m = (l + r) / 2;
build(a, node * 2, l, m); // 初始化左子树
build(a, node * 2 + 1, m + 1, r); // 初始化右子树
maintain(node);
}
void update(int node, int l, int r, int i, T val) {
if (l == r) { // 叶子(到达目标)
// 如果想直接替换的话,可以写 tree[node] = val
tree[node] = merge_val(tree[node], val);
return;
}
int m = (l + r) / 2;
if (i <= m) { // i 在左子树
update(node * 2, l, m, i, val);
} else { // i 在右子树
update(node * 2 + 1, m + 1, r, i, val);
}
maintain(node);
}
T query(int node, int l, int r, int ql, int qr) const {
if (ql <= l && r <= qr) { // 当前子树完全在 [ql, qr] 内
return tree[node];
}
int m = (l + r) / 2;
if (qr <= m) { // [ql, qr] 在左子树
return query(node * 2, l, m, ql, qr);
}
if (ql > m) { // [ql, qr] 在右子树
return query(node * 2 + 1, m + 1, r, ql, qr);
}
T l_res = query(node * 2, l, m, ql, qr);
T r_res = query(node * 2 + 1, m + 1, r, ql, qr);
return merge_val(l_res, r_res);
}
public:
// 线段树维护一个长为 n 的数组(下标从 0 到 n-1),元素初始值为 init_val
SegmentTree(int n, T init_val) : SegmentTree(vector<T>(n, init_val)) {}
// 线段树维护数组 a
SegmentTree(const vector<T>& a) : n(a.size()), tree(2 << bit_width(a.size() - 1)) {
build(a, 1, 0, n - 1);
}
// 更新 a[i] 为 merge_val(a[i], val)
// 时间复杂度 O(log n)
void update(int i, T val) {
update(1, 0, n - 1, i, val);
}
// 返回用 merge_val 合并所有 a[i] 的计算结果,其中 i 在闭区间 [ql, qr] 中
// 时间复杂度 O(log n)
T query(int ql, int qr) const {
return query(1, 0, n - 1, ql, qr);
}
// 获取 a[i] 的值
// 时间复杂度 O(log n)
T get(int i) const {
return query(1, 0, n - 1, i, i);
}
};
void solve() {
int n;
cin >> n;
vector<pii> a(n);
unordered_map<int, vector<int>> dict;//[x, idx]
for(int i = 0; i < n; ++i) {
cin >> a[i].first;
a[i].second = i;
dict[a[i].first].push_back(i);
}
SegmentTree<pii> seg(a);
auto dfs = [&](auto &&dfs, int l, int r) -> int {
if(l > r) return 0;
if(l == r) return 1;
auto [x, idx] = seg.query(l, r);
int res = 0;
int s = l;
int j = ranges::lower_bound(dict[x], s) - dict[x].begin();
int sz = dict[x].size();
for(; j < sz && dict[x][j] <= r; ++j) {
res = max(res, dfs(dfs, s, dict[x][j] - 1));
s = dict[x][j] + 1;
}
res = max(res, dfs(dfs, s, r));
return res + 1;
};
cout<<dfs(dfs, 0, n - 1)<<endl;
}
另一種不用線段樹的作法,時間複雜度同樣是 \(O(n\log{n})\)。
透過事先排序高度,由高至低處理山頂。利用有序結構 map 儲存比當前元素高的山頂,利用 upper_bound 找兩個最近的位置,計算到當前高度要多長的距離 \(max(dis[pre], dis[nxt]) + 1\)。
- 要注意的地方是,更新 map 時必須同一個高度的位置都計算完後才更新,否則會統計到相同高度的位置。
void solve() {
int n;
cin >> n;
vector<pii> heights;
for(int i = 0; i < n; ++i) {
int h;
cin >> h;
heights.emplace_back(h, i);
}
ranges::sort(heights, greater{});
map<int, int> dis;
vector<pii> updates;
dis[0] = 0;
dis[n + 1] = 0;
int ans = 0, pre_h = 0;
for(auto &[h, pos]: heights) {
if(pre_h != h) {
for(auto &[p, d]: updates) {
dis[p] = d;
}
updates.clear();
pre_h = h;
}
auto it = dis.upper_bound(pos);
int nxt = it->first;
it--;
int pre = it->first;
int res = max(dis[nxt], dis[pre]) + 1;
ans = max(ans, res);
updates.emplace_back(pos, res);
}
cout<<ans<<endl;
}
透過單調 stack 可以得到最近比自己矮一點的山頂,要注意的是這裡單調 stack 的 top 元素為被更新的主體,而不是平常拿 top 元素回答當前元素的方式。
透過拓樸排序,可以由入度為 0 的山頂往旁邊矮一點的山頂走,此時更新方式 \(depth[nxt] = max(depth[nxt], depth[cur] + 1)\)。
void solve() {
int n;
cin >> n;
vector<int> a(n + 2);
for(int i = 1; i <= n; ++i) cin >> a[i];
a[0] = inf;
a[n + 1] = inf;
vector<vector<int>> g(n + 2);
vector<int> st = {0};
vector<int> indeg(n + 2, 0), depth(n + 2, 0);
for(int i = 1; i <= n; ++i) {
int &x = a[i];
while(x >= a[st.back()]) st.pop_back();
g[st.back()].push_back(i);
indeg[i]++;
st.push_back(i);
}
st.clear();
st.push_back(n + 1);
for(int i = n; i >= 1; --i) {
int &x = a[i];
while(x >= a[st.back()]) st.pop_back();
g[st.back()].push_back(i);
indeg[i]++;
st.push_back(i);
}
vector<int> q = {0, n + 1};
for(int i = 0; i < q.size(); ++i) {
int pos = q[i];
for(auto &x: g[pos]) {
depth[x] = max(depth[x], depth[pos] + 1);
indeg[x]--;
if(indeg[x] == 0) {
q.push_back(x);
}
}
}
cout<<ranges::max(depth)<<endl;
}
18. Increasing Subsequence¶
經典 LIS 問題,轉移方程 \(LIS(i) = max_{j < i, x_j < x_i}{LIS(j)} + 1\),在找 \(max_{j < i, x_j < x_i}{LIS(j)}\) 的過程若是單純用樸素的方式會有 \(O(n^2)\) 的複雜度。
利用線段樹可以將區間極值回答優化至 \(O(\log{n})\),整體複雜度為 \(O(n\log{n})\)。
我的作法是透過離散化數據,將值域的最長遞增子序列長度存在線段樹中,轉移方程為 \(LIS(x_i) = max_{j < i, x_j < x_i}{LIS(x_i - 1)} + 1\),利用線段樹回答比 \(x_i\) 小的最長遞增子序列。
template<typename T>
class SegmentTree {
// 注:也可以去掉 template<typename T>,改在这里定义 T
// using T = pair<int, int>;
int n;
vector<T> tree;
// 合并两个 val
T merge_val(T a, T b) const {
return max(a, b);
}
// 合并左右儿子的 val 到当前节点的 val
void maintain(int node) {
tree[node] = merge_val(tree[node * 2], tree[node * 2 + 1]);
}
// 用 a 初始化线段树
// 时间复杂度 O(n)
void build(const vector<T>& a, int node, int l, int r) {
if (l == r) { // 叶子
tree[node] = a[l]; // 初始化叶节点的值
return;
}
int m = (l + r) / 2;
build(a, node * 2, l, m); // 初始化左子树
build(a, node * 2 + 1, m + 1, r); // 初始化右子树
maintain(node);
}
void update(int node, int l, int r, int i, T val) {
if (l == r) { // 叶子(到达目标)
// 如果想直接替换的话,可以写 tree[node] = val
tree[node] = merge_val(tree[node], val);
return;
}
int m = (l + r) / 2;
if (i <= m) { // i 在左子树
update(node * 2, l, m, i, val);
} else { // i 在右子树
update(node * 2 + 1, m + 1, r, i, val);
}
maintain(node);
}
T query(int node, int l, int r, int ql, int qr) const {
if (ql <= l && r <= qr) { // 当前子树完全在 [ql, qr] 内
return tree[node];
}
int m = (l + r) / 2;
if (qr <= m) { // [ql, qr] 在左子树
return query(node * 2, l, m, ql, qr);
}
if (ql > m) { // [ql, qr] 在右子树
return query(node * 2 + 1, m + 1, r, ql, qr);
}
T l_res = query(node * 2, l, m, ql, qr);
T r_res = query(node * 2 + 1, m + 1, r, ql, qr);
return merge_val(l_res, r_res);
}
public:
// 线段树维护一个长为 n 的数组(下标从 0 到 n-1),元素初始值为 init_val
SegmentTree(int n, T init_val) : SegmentTree(vector<T>(n, init_val)) {}
// 线段树维护数组 a
SegmentTree(const vector<T>& a) : n(a.size()), tree(2 << bit_width(a.size() - 1)) {
build(a, 1, 0, n - 1);
}
// 更新 a[i] 为 merge_val(a[i], val)
// 时间复杂度 O(log n)
void update(int i, T val) {
update(1, 0, n - 1, i, val);
}
// 返回用 merge_val 合并所有 a[i] 的计算结果,其中 i 在闭区间 [ql, qr] 中
// 时间复杂度 O(log n)
T query(int ql, int qr) const {
return query(1, 0, n - 1, ql, qr);
}
// 获取 a[i] 的值
// 时间复杂度 O(log n)
T get(int i) const {
return query(1, 0, n - 1, i, i);
}
};
void solve() {
int n, x, idx = 1, ans = 0;
cin >> n;
vector<int> a(n);
map<int, int> dict;
for(int i = 0; i < n; ++i) {
cin >> a[i];
dict[a[i]] = 0;
}
for(auto &[x, i]: dict) i = idx++;
vector<int> dis(idx);
SegmentTree t(dis);
for(auto &x: a) {
int val = t.query(0, dict[x] - 1) + 1;
int tv = t.get(dict[x]);
if(val > tv) t.update(dict[x], val);
chmax(ans, val);
}
cout<<ans<<endl;
}
用 sort 離散化會比較快。
void solve() {
int n, x, idx = 1, ans = 0;
cin >> n;
vector<int> a(n);
vector<int> discret(n + 1), dis(n + 1);
SegmentTree t(dis);
for(int i = 0; i < n; ++i) {
cin >> a[i];
discret[i + 1] = a[i];
}
ranges::sort(discret);
discret.erase(unique(discret.begin(), discret.end()), discret.end());
for(auto &x: a) {
x = ranges::lower_bound(discret, x) - discret.begin();
}
for(auto &x: a) {
int val = t.query(0, x - 1) + 1;
int tv = t.get(x);
if(val > tv) t.update(x, val);
chmax(ans, val);
}
cout<<ans<<endl;
}
貪心:
- 嚴格遞增子序列 -> lower_bound
- 遞增子序列 -> upper_bound
void solve() {
int n, x;
cin >> n;
vector<int> g;
for(int i = 0; i < n; ++i) {
cin >> x;
auto it = ranges::lower_bound(g, x);
if(it == g.end()) {
g.push_back(x);
} else *it = x;
}
cout<<g.size()<<endl;
}
19. Projects¶
先離散化座標後 DP,對於 \(proj_i\) 的轉移方程為 \(f(r) = max{f(l - 1)} + p\)
利用 BIT 維護前綴最大值,整體時間複雜度為 \(O(n\log{n})\)
template<typename T>
class FenwickTree {
vector<T> tree;
public:
// 使用下标 1 到 n
FenwickTree(int n) : tree(n + 1) {}
// a[i] 增加 val
// 1 <= i <= n
// 时间复杂度 O(log n)
void update(int i, T val) {
for (; i < tree.size(); i += i & -i) {
chmax(tree[i], val);
}
}
// 求前缀和 a[1] + ... + a[i]
// 1 <= i <= n
// 时间复杂度 O(log n)
T pre(int i) const {
T res = 0;
for (; i > 0; i -= (i & -i)) {
chmax(res, tree[i]);
}
return res;
}
// 求区间和 a[l] + ... + a[r]
// 1 <= l <= r <= n
// 时间复杂度 O(log n)
T query(int l, int r) const {
if (r < l) {
return 0;
}
return pre(r) - pre(l - 1);
}
};
void solve() {
int n, l, r, p;
cin >> n;
vector<tiii> projects(n);
vector<int> pos;
for(int i = 0; i < n; ++i) {
cin >> l >> r >> p;
projects[i] = tuple{l, r, p};
pos.push_back(l);
pos.push_back(r);
}
ranges::sort(projects);
ranges::sort(pos);
pos.erase(unique(pos.begin(), pos.end()), pos.end());
for(auto &[l, r, p]: projects) {
l = ranges::lower_bound(pos, l) - pos.begin();
r = ranges::lower_bound(pos, r) - pos.begin();
}
FenwickTree<ll> t(pos.size());
for(auto &[l, r, p]: projects) {
ll mx = t.pre(l);
t.update(r + 1, mx + p);
}
cout<<t.pre(pos.size())<<endl;
}
先將座標離散化後,因為要計算 \(max{f(l - 1)}\),所以要先處理右端點再處理左端點,避免在計算右端時 \(l\) 時統計到左端點的 \(l\)。
void solve() {
int n, l, r, p;
cin >> n;
vector<tiii> pos;
vector<int> prices(n);
vector<ll> f(n);
for(int i = 0; i < n; ++i) {
cin >> l >> r >> prices[i];
pos.push_back(tuple{l, 0, i});
pos.push_back(tuple{r, 1, i});
}
ranges::sort(pos);
ll pre = 0;
for(auto &[p, isEnd, i]: pos) {
if(isEnd) {
pre = max(pre, f[i]);
} else {
f[i] = pre + prices[i];
}
}
cout<<pre<<endl;
}
20. Elevator Rides¶
這題要用樹形 DP 的概念出發,使用 \(f(s) = \{r, l\}\) 分別儲存兩種不同的狀態。\(r\) 表示當前 s 搭電梯最少需要多少次,\(l\) 表示最後一次剩下多少人。我們不關心前 r - 1 次的順序和每次搭乘人數。轉移方程為 $\(f(S) = min_{i \in S}{G(f(S \oplus i), w_i)}\)$
此時 \(G(f(S \oplus i), w_i)\),嘗試在 \(S \oplus i\) 中加入 \(w_i\)
-
若是 \(l_{S \oplus i} + w_i > x\) :
則此時 \(f(S) = \{r_{S \oplus i} + 1, w_i \}\)
-
若是 \(l_{S \oplus i} + w_i \le x\) :
則此時 \(f(S) = \{r_{S \oplus i}, l_{S} = min(l_{S}, l_{S \oplus i} + w_i) \}\)
\(l_{S}\) 需要儲存的是當前 S 下在 \(r_{S}\) 時最少剩餘人數。
此時時間複雜度為 \(O(n2^n)\)
void solve() {
int n, w;
cin >> n >> w;
vector<int> a(n);
readv(n, a[i]);
int u = 1 << n;
int all = u - 1;
vector<ll> left(u), elevators(u, inf);
elevators[0] = 0;
for(int s = 1; s < u; ++s) {
for(int i = 0; i < n; ++i) {
if(s >> i & 1) {
ll cnt = left[s ^ (1 << i)] + a[i];
ll sub = elevators[s ^ (1 << i)];
if(cnt > w) {
sub++;
cnt = a[i];
}
if(sub < elevators[s]) {
elevators[s] = sub;
left[s] = cnt;
}
if(sub == elevators[s] && cnt < left[s]) {
left[s] = cnt;
}
}
}
}
if(left[all]) elevators[all]++;
cout<<elevators[all]<<endl;
}
21. Counting Tilings¶
\(f(i, pre)\) 表示在第 i 行剩下 pre 可以放的位置,枚舉 \(1 \times 2\) 的位置確認可不可以放得下。時間複雜度為 \(O(nm3^n)\)。
void solve() {
int n, m;
cin >> n >> m;
int u = 1 << n;
int all = u - 1;
vector f(m + 1, vector<ll>(u, -1));
auto check = [&](int s) -> int {//check xx
int cnt = popcount((unsigned) s);
if(cnt & 1) return false;
for(int i = 0; i < n; ++i) {
if(s >> i & 1) {
int j = i + 1;
if(j < n && (s >> j & 1)) {
cnt -= 2;
i = j;
}
}
}
return cnt == 0;
};
auto dfs = [&](auto &&dfs, int i, int s) -> ll {
if(i == 1) {
return check(s);
}
ll &res = f[i][s];
if(res != -1) return res;
res = 0;
int sub = s;
do {
if(check(s ^ sub)) {
res = (res + dfs(dfs, i - 1, all ^ sub)) % MOD;
}
sub = (sub - 1 & s);
} while(sub != s);
return res;
};
cout<<dfs(dfs, m, all)<<endl;
}
透過預處理 check 函數可以將複雜度降至 \(O(m3^n)\)
vector<int> available(u, 0);
for(int s = 0; s < u; ++s) {
int cnt = popcount((unsigned) s);
if(cnt & 1) continue;
for(int i = 0; i < n; ++i) {
if(s >> i & 1) {
int j = i + 1;
if(j < n && (s >> j & 1)) {
cnt -= 2;
i = j;
}
}
}
available[s] = cnt == 0;
}
優化¶
-
DP on profiles(輪廓線 DP)
先定義 1 表示當前被填滿,0 表示當前為空。且 q 表示第 i column 的輪廓線,p 表示第 i + 1 column 的輪廓線,如圖:
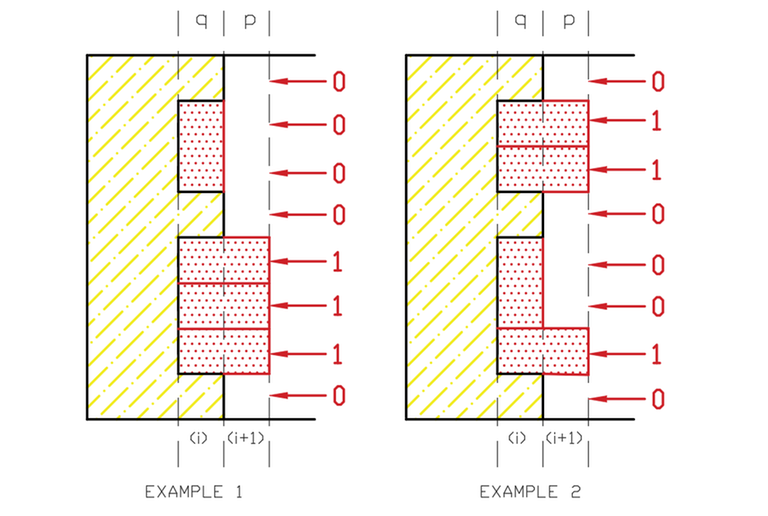
由上面可以得到幾個性質:
-
如果 q 的第 \(j^{th}\) bit 為 1,則表示無法放置水平的磚塊,則 p 的 \(j^{th}\) bit 必為 0。
-
如果 q 的第 \(j^{th}\) bit 為 0,那我們可以放一個水平的磚塊,此時 p 的 \(j^{th}\) bit 會是 1。
-
如果 q 的第 \(j^{th}\) 和 \((j+1)^{th}\) bit 為 0,可以放置一個垂直的磚塊,對應 p 的 \(j^{th}\) 和 \((j + 1)^{th}\) bit 會是 1。
由上面這些規則我們可以定義 \(dp[i][q]\) ,當在第 i column 時有 q 的輪廓線,透過遞迴我們可以將第 i column 填滿產生 i + 1 column 的輪廓線 p。
- pseudo code:
func fills(j, i, p, q): if j == n: dp[i + 1][p] += dp[i][q] return //case 1 if q >> i & 1: fills(j + 1, i, p, q) return //case 2 fills(j + 1, i, p ^ (1 << j), q) //case 3 if j + 1 <= n - 1 && !(q >> (j + 1) & 1): fills(j + 2, i, p, q) dp[0][0] = 1 for i to m: for q to (1 << n): fills(0, i, 0, q) return dp[m][0]上面這個演算法時間複雜度會是 \(O(m \times (2^n \cdot n+ C(n)))\),多出來的 \(C(n)\) 是假設輪廓線為 q 時,則我們至少會需要 n 做 \(fills(j + 1)\),以及多出來的 \(fills(j + 2)\),多出來的部分就是 \(C(n)\) 的總和。
只有當 q 有兩個相鄰的 0 時會同時呼叫 \(fills(j + 1)\) 和 \(fills(j + 2)\),我們要計算的是這個情況的上界 \(C(n)\)。
設 \(totalcalls(j)\) 表示在 q 中 \(j^{th}\) bit 為 0 且相鄰也是 0 時所需的呼叫次數。定義 \(totalcalls(1) = 1\),\(totalcalls(2) = 1\),對於 \(n > 2\) 時有 \(totalcalls(n) = totalcalls(n - 1) + totalcalls(n - 2) = f_n(n_{th} \text{ fibonacci no.})\) ,假設 q 的輪廓線有 k 個 0 ,則 \(O(f_k) = O(\phi^k) \approx O(1.62^k)\),\(\phi\) 為黃金比例。
組合數在 n 個 bit 取 k 個零 \(\binom{n}{k}\) ,所以 \(C(n) = O(\sum_{k}{\binom{n}{k} \cdot \phi^k}) = O((1 + \phi)^n) \approx O(2.62^n)\)。
最後時間複雜度來到 \(O(m \times (n2^n + 2.62^n))\)
-
-
Optimization using Broken Profile DP
觀察上面填磚塊的過程,會發現同一種輪廓線 p 會重複計算很多次(從不同輪廓線 q 得到)。是否可以從這點下手進行優化?
在第 \(i^{th}\) column 按照順序從 0 填到 \(j^{th}\) row 時,可以將此時的輪廓線劃分成 "已經填完" 和 "還沒填" 兩部分。
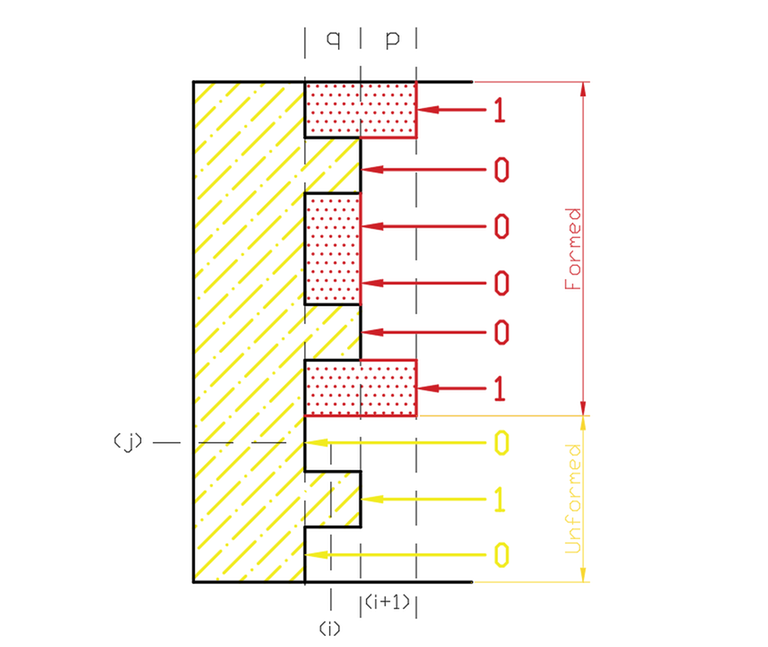
如上圖將輪廓線分成 100001 和 010,可以定義轉移方程 \(dp[i][j][x]\) 表示在填滿 \(i - 1\) column 的情況下在 \(i^{th}\) column 已經填了 \(j^{th}\) row 有輪廓線 x 的方案數。
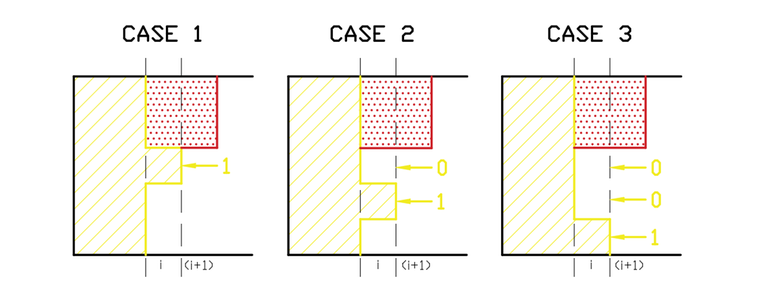
-
如果遇到下一個 cell 為 1 (\(x \& 2^{j + 1} = 1\)),此時不能放水平的磚頭,有轉移 \((i, j, x) \rightarrow (i, j + 1, x'), \text{where } x'=x - 2^{j + 1}\),轉移方程為 \(dp[i][j + 1][x'] += dp[i][j][x]\)
-
下一個 cell 為 0 (\(x \& 2^{j + 1} = 0\)),可以放水平的磚頭,有轉移 \((i, j, x) \rightarrow (i, j + 1, x'), \text{where } x'=x + 2^{j + 1}\),轉移方程為 \(dp[i][j + 1][x'] += dp[i][j][x]\)
-
如果遇到兩個連續的 0,可以放垂直的磚頭,放完後不會改變輪廓線 p,此時的轉移 \((i, j, x) \rightarrow (i, j + 2, x)\),\(dp[i][j+2][x] += dp[i][j][x]\)
-
最後當 (i, n, x) 時表示前面 n bit 都填完了,可以轉移到 i + 1 column 繼續填,此時狀態為 (i + 1, 0, x),有轉移方程 \(dp[i + 1][0][x] = dp[i][n][x]\)
時間複雜度為 \(O(nm2^n)\)
-
const int MOD = 1'000'000'000 + 7;
const int MXN = 10, MXM = 1000;
ll f[MXM + 1][MXN + 1][1 << MXN];
void solve() {
int n, m;
cin >> n >> m;
int u = 1 << n;
int all = u - 1;
f[0][n][0] = 1;
for(int i = 1; i <= m; ++i) {
for(int p = 0; p < u; ++p) {
f[i][0][p] = f[i - 1][n][p];
}
for(int j = 1; j <= n; ++j) {
for(int p = 0; p < u; ++p) {
if(p >> (j - 1) & 1) {
int q = p - (1 << (j - 1));
f[i][j][p] += f[i][j - 1][q];
} else {
int q = p + (1 << (j - 1));
f[i][j][p] += f[i][j - 1][q];
if(j - 2 >= 0 && !(p >> (j - 2) & 1)) {
f[i][j][p] += f[i][j - 2][p];
}
}
f[i][j][p] %= MOD;
}
}
}
cout<<f[m][n][0]<<endl;
}
22. Counting Numbers¶
經典數位DP,套模板
// ref: https://leetcode.cn/discuss/post/tXLS3i/
// 代码示例:返回 [low, high] 中的恰好包含 target 个 0 的数字个数
// 比如 digitDP(0, 10, 1) == 2
// 要点:我们统计的是 0 的个数,需要区分【前导零】和【数字中的零】,前导零不能计入,而数字中的零需要计入
ll digitDP(ll low, ll high) {
string low_s = to_string(low);
string high_s = to_string(high);
int n = high_s.size();
int diff_lh = n - low_s.size();
int mask = 1 << 10;
vector memo(n, vector<ll>(11, -1));
auto dfs = [&](auto&& dfs, int i, int pre, bool limit_low, bool limit_high) -> ll {
if (i == n) {
return 1;
}
if (!limit_low && !limit_high && memo[i][pre] >= 0) {
return memo[i][pre];
}
int lo = limit_low && i >= diff_lh ? low_s[i - diff_lh] - '0' : 0;
int hi = limit_high ? high_s[i] - '0' : 9;
ll res = 0;
int d = lo;
// 通过 limit_low 和 i 可以判断能否不填数字,无需 is_num 参数
// 如果前导零不影响答案,去掉这个 if block
if (limit_low && i < diff_lh) {
// 不填数字,上界不受约束
res = dfs(dfs, i + 1, mask, true, false);
d = 1;
}
for (; d <= hi; d++) {
// 统计 0 的个数
if(pre == d) continue;
res += dfs(dfs, i + 1, d, limit_low && d == lo, limit_high && d == hi);
// res %= MOD;
}
if (!limit_low && !limit_high) {
memo[i][pre] = res;
}
return res;
};
ll ans = dfs(dfs, 0, 10, true, true);
return ans;
}
void solve() {
ll low, high;
cin >> low >> high;
cout<<digitDP(low, high)<<endl;
}
23. Increasing Subsequence II¶
離散化 + BIT 前綴和優化 DP
const int MOD = 1'000'000'000 + 7;
template<typename T>
class FenwickTree {
vector<T> tree;
public:
// 使用下标 1 到 n
FenwickTree(int n) : tree(n + 1) {}
// a[i] 增加 val
// 1 <= i <= n
// 时间复杂度 O(log n)
void update(int i, T val) {
for (; i < tree.size(); i += i & -i) {
tree[i] = (tree[i] + val) % MOD;
}
}
// 求前缀和 a[1] + ... + a[i]
// 1 <= i <= n
// 时间复杂度 O(log n)
T pre(int i) const {
T res = 0;
for (; i > 0; i -= (i & -i)) {
res = (res + tree[i]) % MOD;
}
return res;
}
// 求区间和 a[l] + ... + a[r]
// 1 <= l <= r <= n
// 时间复杂度 O(log n)
T query(int l, int r) const {
if (r < l) {
return 0;
}
return ((pre(r) - pre(l - 1)) % MOD + MOD) % MOD;
}
};
void solve() {
int n;
cin >> n;
vector<int> a(n), pos(n + 1);
for(int i = 0; i < n; ++i) {
cin >> a[i];
pos[i] = a[i];
}
pos.push_back(0);
ranges::sort(pos);
pos.erase(unique(pos.begin(), pos.end()), pos.end());
for(auto &x: a) {
x = ranges::lower_bound(pos, x) - pos.begin();
}
int sz = pos.size(), ans = 0;
FenwickTree<ll> t(sz);
t.update(1, 1);
for(auto &x: a) {
int pre = t.pre(x);
t.update(x + 1, pre);
ans = (ans + pre) % MOD;
}
cout<<ans<<endl;
}